Overview
Fig. 1: Answers to the question “What was your approach to calibration?” (n=189) from a web-based survey of calibration practices in crop modeling (Seidel et al. 2018).
The protocol covers all the steps involved in calibration, namely the choice of default parameter values, observed variables to fit, objective function, parameters to be estimated, numerical algorithm and implementation, and finally of evaluation. The protocol also includes instructions as to documentation to be produced at each step of the calibration. The protocol is intended to be applicable to a wide range of crop growth models and crop development data sets, e.g. covering a number of sites and/or several treatments at one or more sites and different types of measured variables. These can be variables measured over time (phenology, biomass, leaf area index, soil water contents, soil mineral nitrogen contents etc.) or variables measured only at one point in time (e.g. crop yield, yield components, grain protein or grain number at harvest), but for several treatments or environments (we call site/year combinations of measurements “environments”).
Description of the calibration protocol
The proposed protocol for crop model calibration, is composed of eight steps (Fig. 2). Implementation of t he first five steps (the model expertise part of the protocol) require detailed knowledge of the model and the data. No calculations are performed here. The result of these steps is a series of tables that contain all the model-specific information needed for the calculations. The last three steps (the calculation steps) describe the calculations to be done. The protocol includes instructions for each step, and the documentation to be produced in each step. The documentation of all decisions and assumptions is an integral part of the protocol, ensuring transparency and reproducibility of the calibration procedure.
Fig. 2: Schema of calibration protocol. The first five steps involve codifying model expertise. Given that information, the calculation steps 6-8 require no further model-specific inputs (according to Wallach et al. 2024).
Step 1. Choose default parameter values
Only a small fraction of crop model parameters will usually be estimated from the data. The majority of the parameters will remain at their default values. Default values[1] in this context are the pre‑set parameter values provided by the model developers, or taken from an earlier model calibration, intended to represent the most relevant existing parameter values for the studied conditions. Also, for those parameters that are estimated from the data, the starting values for exploring the parameter space are centered around the default values. The optimization method used here, works best, if the default values for parameters to be estimated are reasonably close to the new best values. Therefore, it is important to choose the default values with care. In particular, one should obtain as much information as possible about the cultivar characteristics (maturity class, photoperiod sensitivity, vernalization requirements etc.) and choose default parameter values based on a cultivar as similar as possible to the cultivar in question.
The documentation required here (Table 1) contains the cultivar characteristics and the rationale for the choice of default parameter values.

Table 1 : Example of protocol documentation for step 1, showing cultivar characteristics of the target population variety and of the variety providing the default parameter values. This example is for the French data set and the STICS model.
| Variety | Characteristics |
| Variety of measurements: Apache | A soft winter wheat. Stem elongation – semi-early. Heading – early. Vernalization requires 40 days where full vernalization occurs if daily average temperature is between 3°C and 10°C. There is no vernalization below -4°C or above 17°C. Otherwise there is a proportional reduction in vernalization effectiveness. |
| Cultivar used to provide default parameter values: Soissons | Soissons seems to be close to Apache in terms of vernalization requirements and earliness. |
Step 2. List observed variables and corresponding simulated variables
The purpose of this step is to identify the correspondence between observed and simulated variables. For crop model calibration, it is advantageous to have as many variables as possible, because it provides richer, more diverse information that helps constrain parameters more effectively, reduces equifinality, and improves the model’s ability to represent multiple processes accurately, which leads to more robust and reliable predictions across conditions. Therefore, it is strongly recommended to use all observed or measured variables for calibration that have a corresponding output variable in the model. A simulated variable is assigned to each measured variable. The documentation required for this step is a table with one row for each measured variable, showing also the corresponding simulated variable and the respective unit (Table 2 shows an example).
Table 2: Example of protocol documentation for step 2 and 3, showing observed and corresponding simulated variables as well as their units [9] (step 2) and the group, each parameter is attributed to (step 3), including their order of calibration. This example is for the French data set and the STICS model.
| Name of the observed or required variable | Group for calibration | Name of the simulated variable | Unit of the simulated variable |
| Date_BBCH10 | phenology | ilevs | d |
| Date_BBCH30 | phenology | iamfs | d |
| Date_BBCH55 | phenology | ilaxs | d |
| Date_BBCH90 | phenology | imats | d |
| EarsPerSqM | ears | NA | NA |
| Biomass | plant_biomass | masec_n | t ha-1 |
| N_in_biomassHarvest | plant_N_content | N_in_biomassHarvest | % |
| Grain_Number | grain_number | chargefruit | m-2 |
| Grain_Yield | yield | mafruit | t ha-1 |
| ProteinContentGrain | seed_protein | ProteinContentGrain | % |
Step 3. Define groups of variables and order them
In this step, observed variables are divided into groups. All variables in one group need to have the same unit. For example, data of days to development stages are grouped together in a phenology group. Multiple observations over time of the same variable (e.g., biomass, if there are in-season measurements) will constitute a single group[11] . Other variables, such as observations at crop harvest (e.g. yield, grain number, grain protein content etc.) will each constitute a separate group.
Then, the order in which the variable groups will be used for calibration needs to be defined. The order should be such that estimating parameters to fit variables in one group has little or no effect on the simulated values of variables in previous groups. In the case of modeling crop growth, phenology is usually the first group, since while changing simulated phenology usually has a major effect on simulated values of other variables, changing the simulated values of other variables often has little or no effect on simulated phenology.
If there is little or no feedback in between variable groups, then the fit to each variable group will hardly change when subsequent groups are fit, so the parameter values found for each group will be a good approximation to the best parameters considering all the data. If, however, there is substantial feedback, which is quite typical in crop models, then the parameter values found for each group will no longer give a good fit after all groups have been considered. This is taken into account in the later steps of the protocol. The required documentation for this step , which is combined with the documentation for step 2, shows the group and order for each observed variable (Table 2).
Step 4. Identify the major parameter(s) for each group of variables
The purpose of this step is to identify the major parameters for each variable group. The main role of the major parameters is to reduce bias. The major g parameters for a group of variables should have an effect on the simulated values in all environments. Nearly additive parameters, i.e. parameters that have a similar effect across all environments, can be good choices as major parameters, as they make the model bias nearly zero for the associated variable. An example of a major parameter is thermal degree days to a development stage, since increasing the required number of degree days will, in general, increase the days to the stage by a similar amount for all environments.[15] [16] Parameters that describe the effect of stresses, which only affect the simulated values if the stresses are present, will not be bias-reducing parameters.
There is a strict limit[17] on the number of major parameters for each group, to avoid over-parameterization. If there is only one measured variable in the parameter group (e.g. yield), there can only be[18] one major parameter. For variables with at least two measurements in some environments (e.g. biomass with in-season measurements) there can be [19] at most two major parameters (for example, one that determines rate of increase during vegetative growth and a second that determines rate of increase during reproductive growth). For phenology, there can be as many major parameters as observed development stages with simulated equivalents. However, each phenological major g parameter must affect the time to a different stage. If no parameter acts across nearly all environments for a given variable, then there may be no major parameter for that variable, only candidate parameters (see Step 5).
The required documentation here is a table which shows the major parameters for each variable group (see example in Table 3).
Table 3: Example of protocol documentation for step 4, showing major parameters for the different variable groups with default values, lower and upper boundaries[20] and a short explanation and unit of the parameter. This example is for the French data set and the STICS model.
| Name of the parameter | Group | Default value | Lower bound | Upper bound | Short explanation (and units if possible) |
| stlevamf | phenology | 212 | 150 | 400 | cumulative thermal time between the stages LEV (emergence) and AMF (maximum acceleration of leaf growth, end of juvenile phase) (degree-d) |
| stamflax | phenology | 367 | 150 | 500 | cumulative thermal time between the stages AMF (maximum acceleration of leaf growth, end of juvenile phase) and LAX (maximum leaf area index, end of leaf growth ) (degree-d) |
| stdrpmat | phenology | 700 | 500 | 900 | cumulative thermal time between the stages DRP (starting date of filling of harvested organs) and MAT (maturity) degree-d) |
| efcroiveg | plant_biomass | 4.25 | 3 | 6 | maximum radiation use efficiency during the vegetative stage (AMF = maximum acceleration of leaf growth, end of juvenile phase – DRP=starting date of filling of harvested) (g.MJ-1 organs) |
| efcroirepro | plant_biomass | 4.25 | 3 | 6 | maximum radiation use efficiency during the grain filling phase (DRP= starting date of filling of harvested organs – MAT= maturity), (g.MJ-1) |
| Vmax2 | plant_N_content | 0.05 | 0.002 | 0.1 | maximum specific N uptake rate with the high affinity transport system (µmole.cm-1 h-1) |
| cgrain | grain_number | 0.036 | 0.03 | 0.04 | slope of the relationship between grain number and growth rate (grains.g-1.d) |
| vitircarbT | yield | 0.0007 | 0.00005 | 0.002 | rate of increase of the C harvest index vs thermal time (g grain.g-1.d-1) |
| vitirazo | seed_protein | 0.0145 | 0.001 | 0.04 | rate of increase of the N harvest index vs time (g grain.g-1.d-1) |
Step 5. Identify the candidate parameters for each group of variables
The candidate parameters are those parameters that are likely to explain a substantial part of the variability between environments that remains after the major parameters are estimated. Each of these parameters will be tested (in the next step) for the respective group of variables, and will only be included in the final list of parameters to estimate if estimation leads to a sufficient improvement in fit to the data. The candidate parameters should be ordered from supposedly most to supposedly least important. The number of candidate parameters is not limited, but it has a significant impact on computational time . The required documentation here is a table with the candidate parameters for each variable group (see example in Table 4).
Table 4: Example of protocol documentation for step 5, showing candidate parameters for the different variable groups with default values, lower and upper boundaries and a short explanation and unit of the parameter. This example is for the French data set and the STICS model.
| Name of the parameter | Group | Default value | Lower bound | Upper bound | Short explanation (and units if possible) |
| jvc | phenology | 55.91 | 25 | 60 | number of vernalizing days (d) |
| sensrsec | phenology | 0.5 | 0 | 1 | index of root sensitivity to drought (1=insensitive) (without dimension) |
| belong | phenology | 0.012 | 0.005 | 0.03 | parameter of the curve of coleoptile elongation (degree.day-1) |
| jvcmini | phenology | 7 | 2 | 15 | minimum vernalizing days required (d) |
| stressdev | phenology | 0 | 0 | 1 | maximum phasic delay allowed due to stresses (without dimension) |
| dlaimaxbrut | plant_biomass | 0.00047 | 5E-06 | 0.005 | maximum rate of the setting up of LAI (m2 leaf.plant-1.degree-d-1) |
| durvieF | plant_biomass | 200 | 40 | 300 | maximal lifespan of an adult leaf expressed in summation of Q10=2 (2**(T-Tbase)) (without dimension) |
| vlaimax | plant_biomass | 2.2 | 1.5 | 2.5 | ulai at the inflexion point of the function DELTAI=f(ULAI), where ulai is the relative development unit for LAI (without dimension) |
| psisto | plant_biomass | 15 | 11 | 25 | potential of stomatal closing (absolute value) (bars) |
| psiturg | plant_biomass | 4 | 1 | 15 | potential of the beginning of decrease of the cellular extension (absolute value) (bars) |
| croirac | plant_N_content | 0.12 | 0 | 0.5 | elongation rate of the root apex (cm.degree-d-1) |
| draclong | plant_N_content | 80 | 1 | 1000 | maximum rate of root length production per plant (cm.plant-1.degree-d-1) |
| nbjgrain | grain_number | 30 | 5 | 40 | number of days used to compute the number of viable grains (d) |
| pgrainmaxi | yield | 0.0407 | 0.03 | 0.065 | maximum grain weight (at 0% water content) |
| cgrainv0 | yield | 0 | 0 | 0.07 | fraction of the maximal number of grains when growth rate is zero |
Step 6. Select parameters to estimate for each group and estimate their values
In this calculation step, each group of variables is treated separately, in the order chosen in step 3 (Table 2). A list of parameters to estimate for each group is initialized with the major parameter(s), and then each candidate parameter is tested. The major parameters for the group are estimated using ordinary least squares (OLS), and the corrected Akaike Information Criterion (AICc, Brewer et al., 2016; Chakrabarti and Ghosh, 2011) is calculated as
where SS is the sum of squared errors for all variables in the group, n is the number of data points and p the number of estimated parameters. This assumes that all model errors for the group are independent and identically normally distributed.
Once the major parameters have been estimated, each candidate parameter in turn is added tentatively to the list of parameters to be estimated. If estimating all the parameters on the list reduces AICc below the previous smallest value, the candidate is kept on the list of parameters to be estimated. Otherwise, the candidate is removed from the list of parameters to be estimated, and returns to its default value (see flow diagram in Fig. 3). AICc is a standard model selection criterion, designed to choose the best predicting model even if none of the proposed models is the true model (Aho et al., 2014).
[21] A first required documentation table here shows the result of adding each new candidate parameter, for each variable group (see example in Table 4[22] [23] ). The optimum parameter values and the fit to the measured data after this step are combined with the documentation of step 7 (Table 5, Table 6[24] [25] ).
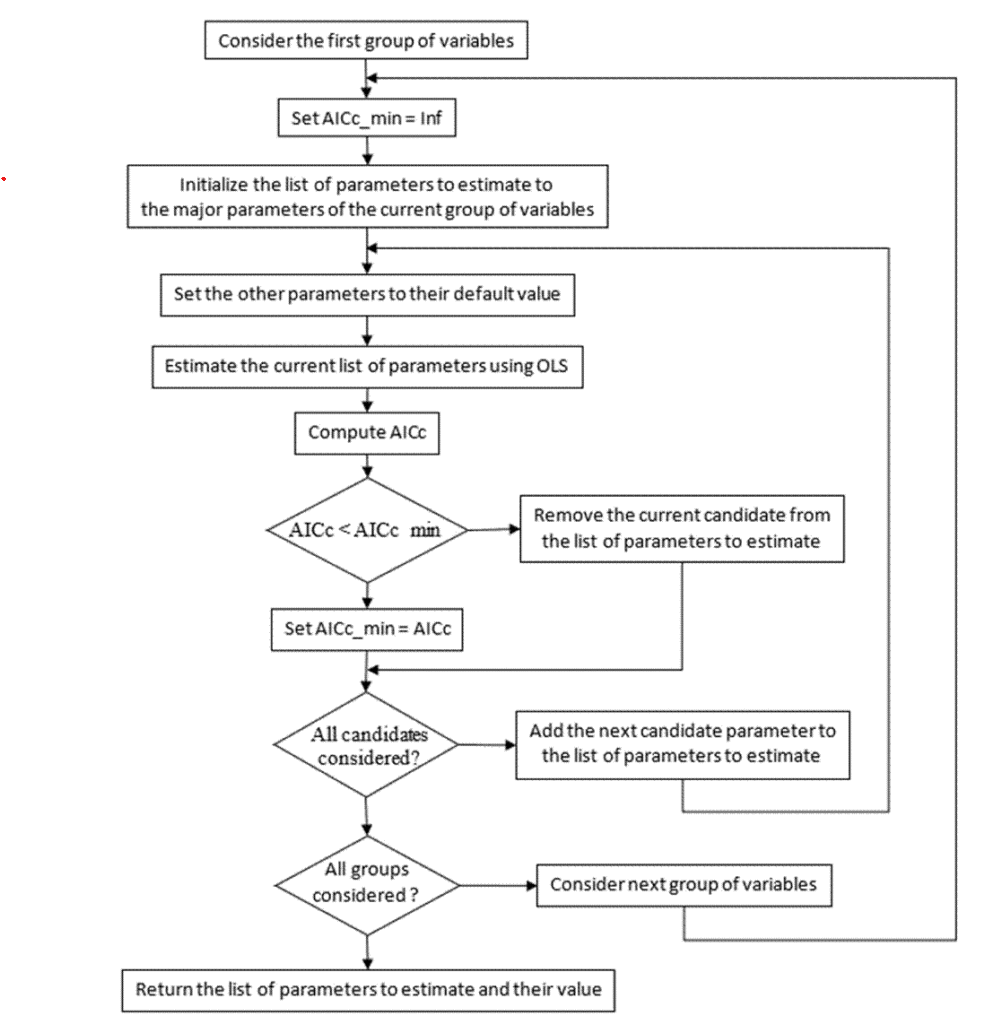
Fig. 3: Flow diagram for the selection of parameters to estimate, and first estimation of their values for one variable group. This is done for each variable group in step 6 of the protocol (Wallach et al. 2024).
Step 7. Estimate all selected parameters together with WLS, using all variables together
In this step, all the selected parameters from step 6 are estimated together, using all the data, using weighted least squares (WLS). The objective function, to be minimized, is a sum of terms, one for each variable group. The term for each group is the sum of squared errors for that group, divided by errVar:
where SS is the sum of squared errors for all variables in the group from step 6, n is the number of data points and p the number of estimated parameters in step 6. The required documentation table here shows the estimated parameter values after steps 6 and 7 (see example in Table 5). [26] [27]
Step 8. Evaluate goodness-of-fit
In this step, metrics of goodness-of-fit are calculated for the simulations using the default parameter values, values after step 6 and using the parameter values after step 7. The required documentation table here shows the metrics for goodness-of-fit at each stage. An example is shown in Table 6 and Supplementary Table S. Additional metrics could also be calculated. Graphs of simulated versus observed values for each variable should also be produced (see example in Supplementary Figures S1-S3). [29]
Discussion
Before starting calibration, some aspects need to be considered: Some variables might need to be transformed before calibration, to give them comparable weights.[31] [32] For example, biomass measurements over time go over a wide range of values over the growth period. This is associated with an increase of standard deviation of model error. Therefore, biomass measurements should be replaced by the natural logarithm of biomass. The log transformation will make the standard deviations approximately constant for all dates. Similarly, a log transformation should be used for any other variables expected to vary over a wide range over time.
In CroptimizR (REF), the Nelder-Mead simplex algorithm is currently used to find optimal parameter values, both in step 6 and step 7 (Nelder and Mead, 1965). [33] However, use of the simplex is not an obligatory part of the protocol. Other optimization algorithms could be used. [34]
Software tools
The open-source R package CroptimizR automates the implementation of the AgMIP Calibration protocol and the generation of associated diagnostics. More broadly, CroptimizR connects crop models or platforms (e.g. STICS, DSSAT, APSIM, SQ2) with parameter estimation packages (e.g. BayesianTools, nloptr) through the development of wrappers, while providing functionalities specifically tailored to crop modeling. Further details on the available methods, criteria, and features can be found on the CroptimizR github page (https://github.com/SticsRPacks/CroptimizR/) and in the package documentation. An example of the protocol applied using this package is also available here: https://sticsrpacks.github.io/CroptimizR/articles/AgMIP_Calibration_Protocol.html.
References see publication page
Maybe to add here links to all our papers (and in future also papers applying the protocol) with their doi links and very short statement of the key development (or testing) the paper involves?
Seidel, S. J.; Palosuo, T.; Thorburn, P.; Wallach, D. (2018): Towards improved calibration of crop models – Where are we now and where should we go? In: European Journal of Agronomy 94, S. 25–35. DOI: 10.1016/j.eja.2018.01.006.
…
Twenty Twenty-Five
email@example.com
+1 555 349 1806